
Webスクレイピングは、Webサイト上のコンテンツやデータを自動的に抽出・収集する手法であり、競合調査やデータ分析、AI開発などのための情報収集手段として注目されている。
例えば、SNSや電子掲示板の書き込みを元に自社サービスの評判を調査する際、Webスクレイピングを活用することで、非常に短時間で調査することが可能となるわけである。
ここでWebスクレイピングそのものが問題というわけではないのだが、情報を自動収集するという性質上、無自覚に実行すると複数の法領域にまたがるリスクを抱える。
多くのサイトでも議論されているところかと思うが、備忘録もかねて主要な論点を整理しておく。
利用規約
まず最初に問題になるのが、収集先となるWebサイトやSNSの利用規約となる。
いくつかのECサイトやSNSでは、スクレイピング等の自動取得行為を明確に禁止している。
この規約に反してデータ取得を行えば、アカウント停止や損害賠償請求のリスクがある。
これに関しては、後述の訴訟のように「ログインせずにアクセスできる公開データ」だけを取得対象にするなら利用規約の効力が及ばないと判断される可能性もあるが、正直日本ではセーフとまでは言い切れるほどの判例や庁見解が揃っていないと思う。
よって、利用規約でスクレイピングを禁止する旨が記載されていれば、スクレイピング行為は控えた方が無難である。
米国の議論(参考)
米国地裁の訴訟であるMeta v. Bright Dataでは、「公開情報については利用規約の効力が制限され得る」という判断が示されている。
ただし、あくまで米国での判断であり、事案依存性が強いという点から、日本でも同様に安全とは言えない。
基本的には公式APIを使うこと
もし情報収集したいSNS等に公式APIがあれば、そちらから情報取得するのが安全である。
もし公式APIがあるにも関わらず、スクレイピングで情報収集しようとする行為は利用規約違反となる可能性が高い。
公式APIがあればWebサイトの利用規約とは別にAPI利用規約が公開されているかと思うので、利用の際はAPI利用規約も遵守する必要がある。
著作権法
スクレイピング対象には、テキスト・画像・動画などの著作物が含まれ得る。
日本の著作権法では、著作権法30条の4により、AI学習などの情報解析目的であれば、原則として著作物の利用が認められる。
ただし、取得データをそのまま掲載する行為は認められない。
掲載する場合は、非類似レベルや統計データへの加工といった対応が必要になる。
個人情報保護法
スクレイピング対象に個人情報が含まれる場合、リスクは一気に高まる。
「公開されているから自由に使える」とは限らず、目的外利用、要配慮個人情報(病歴や犯罪歴など)の取得、第三者提供するといった場合は、個人情報取得に本人同意が必要となる。
一方、現在の個人情報保護法の改正方針案によれば、統計情報等の作成(統計情報等の作成と整理できるAI開発等も含む)のみの利用なら本人同意取得不要とする方針が示されている。
ただし、これはあくまで2026年3月時点では方針案レベルであり、確定ルールではない点に注意が必要である。
改正案については、以下の記事でも触れている。
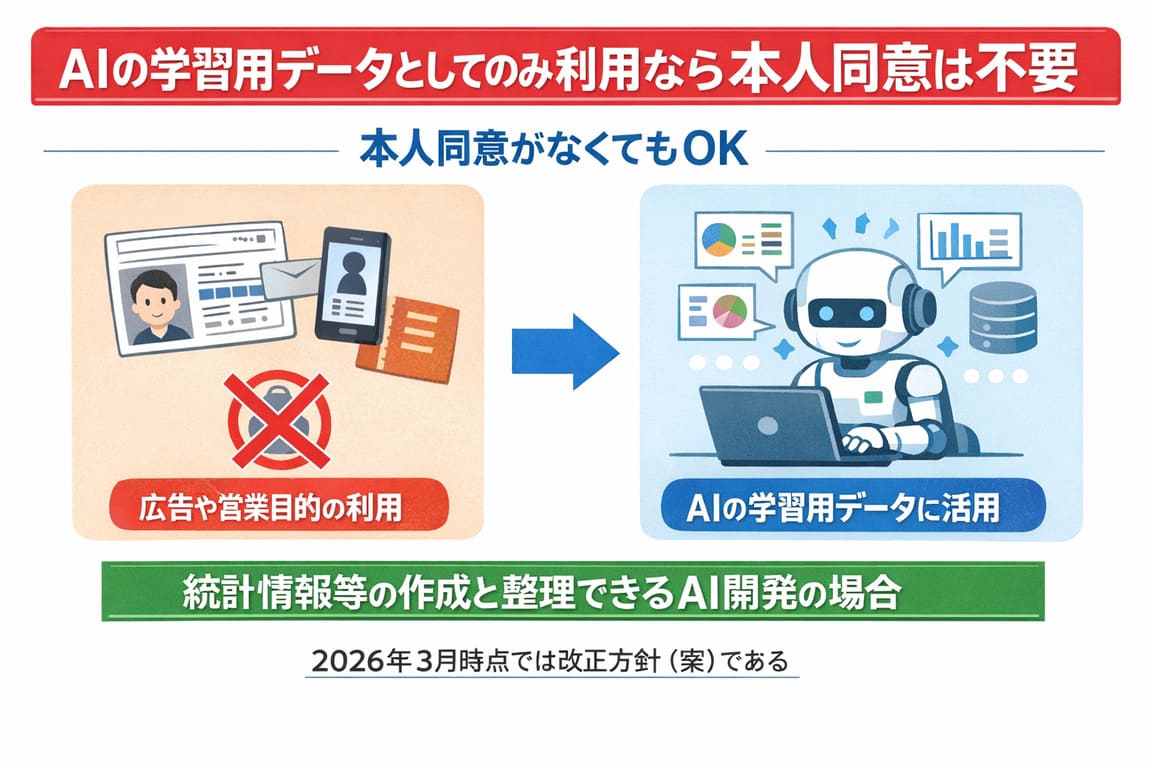
個人情報保護法では、原則として、利用目的の通知またはHP上等での公表を行っておけば、個人情報取得・利用の際の本人同意は不要である。 一方、...
基本的には、個人情報は取得しない、適切に匿名化する、といった対応が必要となる。
不正競争防止法
一般公開されていない営業秘密を不正にスクレイピングした場合、営業秘密の不正取得(不正競争防止法違反)となる場合がある。
公開情報であればともかく、ログインを要する情報の場合はリスクが生じることとなる。
刑法(偽計業務妨害、電子計算機損壊等業務妨害)
スクレイピングは、リクエストの頻度が多すぎると刑事問題にも発展すし得る。
具体的には、サービス提供に支障が出るほどサーバーに過剰な負荷をかける程の頻度になると問題になる。
この問題となる頻度を定量的に判断するのが難しく、一見すると大した頻度でないように見えても、サーバー能力等との兼ね合いで、現実に障害が発生すると問題とされる可能性が高まるようである。
過去に岡崎市中央図書館事件というものがあり、この事件では、約1秒1アクセス程度という頻度にも関わらず、実際に閲覧障害が発生したという事情から、偽計業務妨害容疑で逮捕されている(業務妨害の強い意図が認められないとして、後に起訴猶予処分となった)。
その他
ログインしないと閲覧できないサイトへのスクレイピングは、相当リスクが上がる。
利用規約違反の認定が容易となるし、ログイン認証の突破は、不正アクセス禁止法違反ともなり得る。
またWebサイトには、検索エンジンクローラーに対し、Webサイト内のどのページをクロールしてよいか/拒否すべきかを指示するテキストファイルとして「robots.txt」というものがある。
このrobots.txt自体は、法的拘束力を持つものではない。
ただし、サイト運営者の明確な意思表示と評価されるため、これを無視すると後の紛争で不利に働く可能性がある。
実務的な安全ライン
最後に、スクレイピングを検討する際の実務上の対応策を整理しておく。
- 利用規約でスクレイピング行為が禁止されていれば避ける
- 公式APIがあればそちらを利用する(API利用規約にも注意)
- ログイン不要な公開情報のみをスクレイピング対象にする
- アクセス頻度を厳格に制御する
- 個人情報は原則扱わない(収集した場合は適切に加工・削除)
- 取得データはそのまま公開しない
- robots.txtを尊重する
利用規約の章でも述べた通り、利用規約でスクレイピングを禁止する旨が記載されている場合は、米国地裁の判断があるとはいえ、公開情報であろうとグレーゾーンと考えて避けた方が安全だと思う(公開情報は明確に除外する旨が規定されていれば別だが)。